

Guida alla lettura ottica
[06] Oltre la lettura ottica
Acquisito il documento da elaborare, e terminata l’eventuale fase di image pre-processing, si passa alla fase di lettura vera e propria.
In funzione delle caratteristiche del documento e della configurazione del software, i motori di riconoscimento si occuperanno di “leggere” i dati di interesse, così da renderli disponibili per le fasi successive. E’ in questo punto che entra in gioco un altro concetto cardine nel mondo della lettura ottica: la confidenza di lettura.
La confidenza di lettura (talvolta indicata anche come “accuratezza”) ci indica in che misura il software è sicuro di aver letto correttamente un certo valore: è quindi rappresentata su scala 0-100, e quanto più è alta, tanto più è indice di una elevata sicurezza da parte del software.
E qui nasce un’altra domanda alla quale spesso chi è del settore è costretto a rispondere: qual è la % di riconoscimento del software OCR?
Prima di tutto bisogna distinguere due aspetti: il primo riguarda la % di confidenza rilasciata dal motore, così come derivante dalla lettura di un campo; il secondo riguarda la % di confidenza calcolata dal software, a valle di ulteriori analisi e ragionamenti.
Circa la confidenza rilasciata dall’ “OCR”, esistono diversi approcci in materia: alcuni software calcolano la confidenza di lettura di un campo facendo la media delle confidenze dei singoli caratteri che compongono quel campo; altri, assegnano al campo la confidenza più bassa rilevata tra i caratteri che compongono il campo; altri ancora calcolano la confidenza dell’intera pagina, senza palesare i valori di confidenza del singolo campo o del singolo carattere. Tralasciando quest’ultima modalità che è propria della soluzioni più commerciali, è evidente come il primo approccio abbia evidenti limiti nella elevata possibilità di generare “falsi positivi”. Un solo carattere con bassa confidenza infatti, potrebbe non pesare nella valutazione della confidenza del campo a fronte di numerosi caratteri letti con confidenza molto elevata, dando origine ad un indice di accuratezza ingiustificatamente elevato; viceversa, ricordando che un campo è errato anche se UN SOLO carattere è errato, l’approccio conservativo volto a identificare come confidenza del campo il valore più basso riscontrato tra le confidenze dei caratteri che lo compongono risulta il metodo più saggio, sebbene penalizzato quanto ad appeal verso il cliente, affascinato da valori di accuratezza che non di rado sono promessi – ma solo promessi – addirittura al 99,9%.
Fatta questa premessa, il lettore sarà lieto di conoscere che un indice di accuratezza universale non esiste, sia perché ogni progetto è storia a sé, sia perché la confidenza di lettura dei motori di riconoscimento non è il punto di arrivo della lettura ottica, anzi: è solo il punto di partenza. L’attività di lettura di un dato, infatti, può e deve essere seguita da tutti i controlli possibili utili a incrementare o diminuire la confidenza di lettura da parte del motore: in poche parole, bisogna andare al di là del recognition rate, mettendo in atto ogni possibile controllo utile ad evitare falsi positivi da una parte, e falsi negativi dall’altra. Un esempio banale è la lettura del campo “codice fiscale”: supponiamo che il motore abbia letto il campo con una confidenza di lettura elevata, superiore al 90%; siamo pronti a scommettere che il dato sia effettivamente corretto? O magari è il caso di applicare un controllo aggiuntivo, abilitando la validazione del checksum del codice fiscale? In questo caso un esito superato ci consentirebbe di aumentare la confidenza di lettura a 100, mentre un esito negativo farebbe sprofondare l’indice di accuratezza del campo a ZERO, nonostante l’elevato livello di accuratezza rilasciato dal motore.
L’esempio del codice fiscale è il caso più semplice: le moderne soluzioni di lettura ottica consentono di implementare controlli molto approfonditi e dettagliati, in grado di correlare i valori provenienti da diversi campi e interagire con dati presenti su file o tabelle esterne, in modo da auto-validare le informazioni lette, ed intercettare possibili errori sia di lettura che di compilazione (non dimentichiamo che il fine ultimo è avere la disponibilità delle informazioni contenute sui documenti, ma a condizione che tali informazioni siano plausibili: che senso avrebbe conservare in anagrafica una data di nascita futura, o un codice fiscale di 15 caratteri?).
Al di là della confidenza di lettura e di percentuali che lasciano il tempo che trovano, è fondamentale che il software di data-capture metta a disposizione tutti gli elementi e le funzionalità utili a formulare ipotesi concrete di affidabilità sostanziale del dato, andando oltre il risultato scaturito dalla sola attività di lettura ottica.
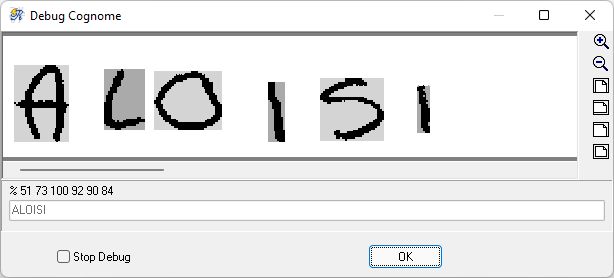
Un cognome riconosciuto con bassa confidenza (51): l’esito positivo della verifica in anagrafica fa sì che il dato non sia sottoposto a verifica operatore.